
数据库优化
一.日志文件优化
1.联机日志:IO ---放在写性能好的磁盘raid1+0,分开和数据文件控制文件存放,一个组下的日志成员分开存放,可避免日志文件的丢失和IO的性能
log--等待事件的优化
log file switch---联机日志大小不够
log file sync---日志缓冲区不够,磁盘IO的问题造成同步写等待
项目中一般3-5个日志文件组,或者5-8个日志文件组
加大日志成员,或者增加日志组解决日志等待时间
日志的切换在15-30min是正常现象
select recid,to_char(first_time,‘yyyy-mm-dd hh24:mi:ss’ )from v$log_history ;//查看日志切换时间
现在日志文件大小50m---5s/1(5秒钟切一次)----想要15分钟且一次日志文件(日志文件应设置的大小=12*15*50 是所有日志组加起来的大小)
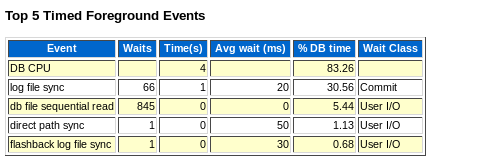 基本是IO的性能瓶颈
基本是IO的性能瓶颈
2.归档日志:保证归档日志的完整性,为归档日志做备份(cp 拷贝到其他地方,rsync同步到其他第方,rman备份归档日志)
保证空间足够,归档放在闪回区
db_recovery_file_dest_size=<> //归档日志放到读写性能好的磁盘中,不要和联机日志放到一起
db_recovery_file_dest //
在告警日志中可以看到归档日志的空间,如果闪回区使用了80%我们就要增加空间
二、数据文件优化
IO
1.每一个表空间下的数据文件放到不同磁盘,不同分区,避免IO的争用
2.每个对象/用户都给他指定一个表空间
v$datafile
select d.file#,name, phyblkrd ,phyblkwrt from v$datafile d ,v$filestat f where d.file#=f.file# //查看文件对物理读写的情况,确定热点文件,热点文件需分开放
3.segment 段
undo段:用户对数据操作的前镜像,一个段的大小,最大为32G,一个事务的大小不能超过32个G,一个段分配给一个事务使用。用户的事务操作达到了33G:1.限制事务的大小,2.建成大表表空间,3.使用自动管理,就会使用undo段
临时段:一般可以不用管,创建默认表空间创建的。存放临时数据,做导入导出时,会用到,做排序时,PGA不够就会使用临时段,临时段不能太大,排序会花大量的时间,也不能太小,会不够存放,不要设置为自动增长,使用默认建库时创建的100m。
数据段/表段:用户在执行DQL操作时,很长时间都不能返回结果,查看段的使用情况。使用了delete 操作,这个块就不会被使用,但是查询的时候还会进行全表扫描,造成执行语句非常慢。
select table_name
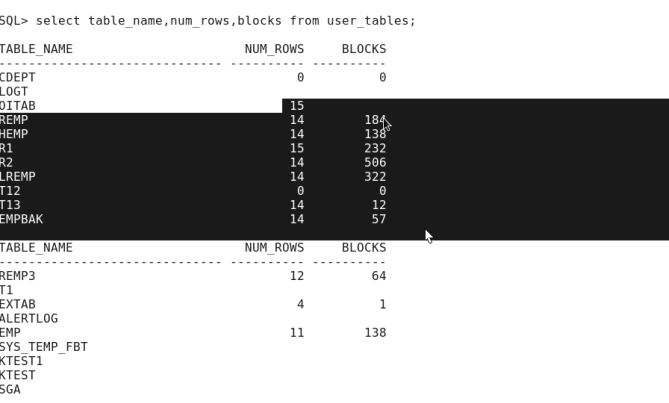 logt表中为0的情况是因为没有收集统计信息
logt表中为0的情况是因为没有收集统计信息
exec dbms_stats.gather_table_stats('TABLE','LOGT') //为logt表做统计信息
查询放到哪一个block中

排名从2开始显示

删除排名为2以后的记录,留下排名为1的记录

一条语句基本上占用一个block

空间回收:
方法一:alter table logt move ; //缩小空间
方法二:

三、控制文件优化:记录数据库的结构与行为,rman的备份信息,快照信息,闪回信息,ckpt事务的队列信息都会记录到控制文件中。
少去触发ckpt,当日志切换的时候会触发,减小控制文件的大小可以优化控制文件
保证控制文件的大小在100m以内,超过100m出现问题时,我们需要重建控制文件,由于重建控制文件我们需要当机,我们需要慎重重建控制文件。
lgwr--- 优化方法,多跑一个lgwr,一个数据库中只有一个lgwr,多跑一个需要增加节点,;增加IO
32--2g/s
64--4g/s
dbwr--- 优化方法:增加dbwr进程
0-9 10g以前
0-9 a-j 10g可以达到20个
0-9 a-z 11g可以到达26个
db